As generative AI (GenAI) becomes central to enterprise innovation, companies are quickly discovering that the quality of their data makes or breaks these initiatives. Poor data quality creates a ripple effect—compromising model training, leading to skewed outputs, and ultimately resulting in misguided decisions and lost business value.
At Trinet Technologies, we believe the foundation of any successful GenAI strategy lies in trusted, well-curated data. High-performing AI models do not start with algorithms—they start with datasets that are accurate, complete, timely, and ethically sourced.
Core vs. Contextual Data: Getting Both Right Matters
GenAI relies on two critical layers of data: core and contextual.
Core data forms the foundation of large language models (LLMs). This is the structured, labeled, high-volume data that enables GenAI to understand patterns, relationships, and logic.
Contextual data, on the other hand, is what breathes relevance into GenAI. It captures specific environmental, linguistic, or business nuances, allowing models to generate outputs that are personalized, localized, and actionable.
To maintain the integrity of these datasets, organizations must ensure:
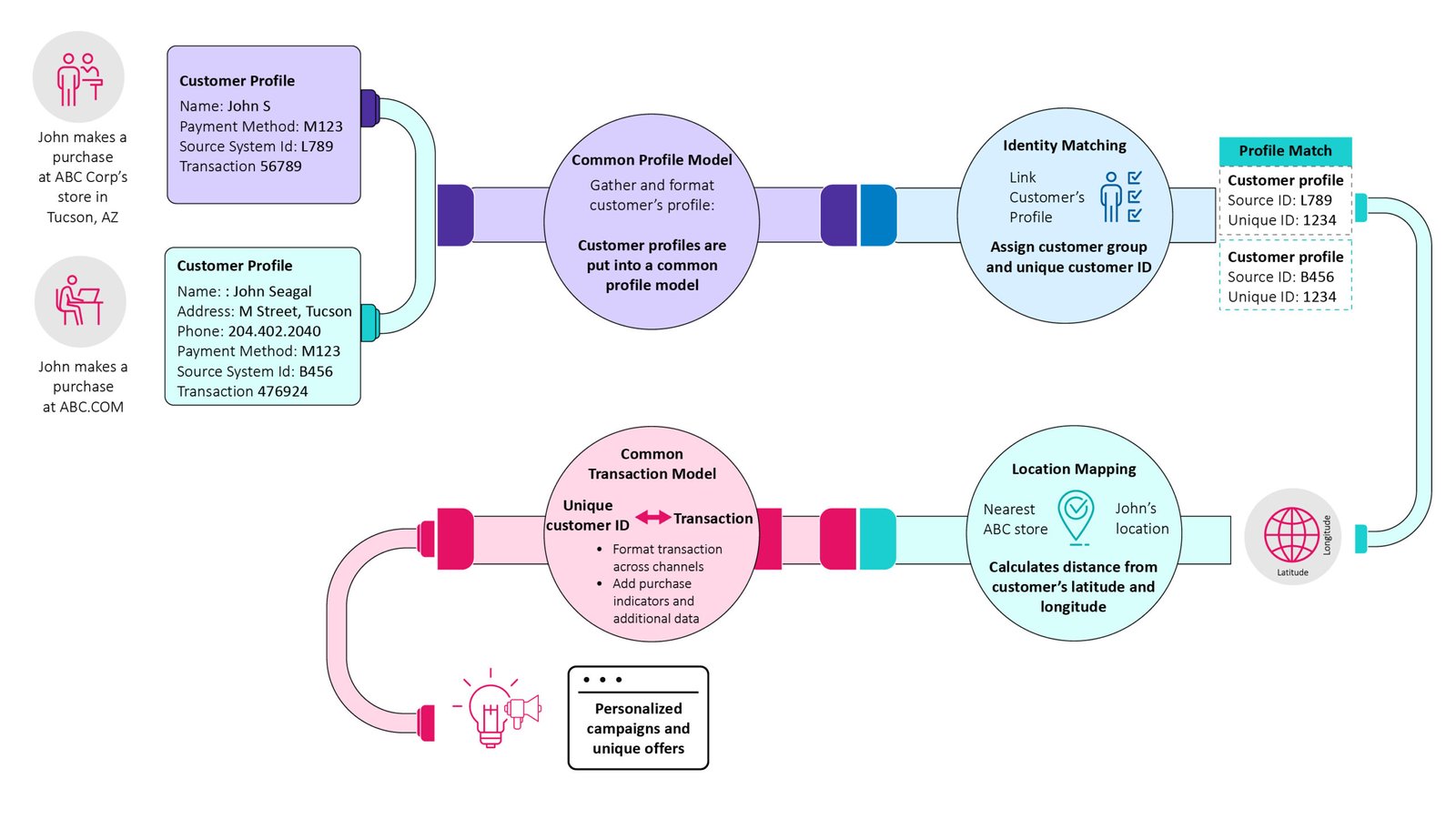
- Contextualization: Tailoring data to specific users, regions, or business goals. For example, a healthcare brand improved physician engagement by combining diverse marketing, interaction, and feedback data into a centralized, quality-controlled dataset.
- Comprehensiveness: Ensuring all user segments, markets, and scenarios are represented, especially for models that operate across regions.
- Bias Mitigation: Reducing bias through iterative validation, prompt engineering, and inclusive data sourcing.
- Regulatory Compliance: Ensuring privacy laws like GDPR or HIPAA are embedded into data governance practices, especially with personally identifiable information (PII).
What Undermines GenAI: Common Data Quality Pitfalls
At Trinet, we frequently see enterprises rushing into GenAI without preparing their data foundations. These six data quality challenges often hold projects back:
- Unlabeled or Poorly Labeled Data: When data lacks clear tags or metadata, LLMs struggle to interpret meaning—leading to hallucinations or incorrect predictions. Organizations should invest in centralized, searchable, and well-structured datasets to improve discoverability and trust.
- Incomplete or Missing Values: Data gaps create blind spots in model training. Robust quality platforms can detect and flag these exceptions, allowing teams to either retrieve source values or apply contextual defaults intelligently.
- Inaccurate or Inconsistent Data: Data inaccuracies—like mismatched metrics between systems—erode confidence. Automating validation workflows and routing corrections to data owners ensures models are trained on reliable facts.
- Data Freshness and Timeliness: Outdated inputs reduce GenAI’s relevance. With data observability platforms, teams can track load delays, monitor stale records, and continuously verify data recency.
- Duplicate Entries: Redundant records skew outcomes and inflate perceived trends. Intelligent deduplication using rules-based matching (e.g., customer name, phone, and email) keeps datasets lean and trustworthy.
- Data Inconsistency Across Systems: If a user is active in your CRM but not in your analytics platform, your segmentation is flawed. A single source of truth, defined and enforced across platforms, ensures accurate insights.
"At Trinet Technologies, we work with enterprises to turn fragmented, inconsistent datasets into AI-ready assets. Clean data is not just about accuracy—it is about enabling innovation, building ethical systems, and earning user trust.”
Scaling GenAI Requires a Strong Data Quality Framework
Trinet Technologies recommends a six-step framework for any organization looking to scale its GenAI programs responsibly:
- Align your quality goals with business and GenAI outcomes. Secure C-level sponsorship to embed data stewardship across departments.
- Choose a single function—like customer support chatbots or marketing content generation—and assess current data gaps. Learn fast, iterate, and scale.
- Define roles (data owners, stewards, governance leads), document processes, and establish KPIs that track accuracy, completeness, and resolution speed.
- Launch a GenAI use case with built-in data quality checkpoints. Create dashboards, reusable rules, and feedback loops to iterate and expand coverage.
- Build remediation workflows that allow fixes at their origin. Use collaborative governance tools to track issues and ensure accountability.
- Treat data quality as a living process. Deploy observability tools that detect anomalies, measure progress, and adapt quality thresholds as business needs evolve.






